Beyond the Prompt: What Loop Engineering Actually Means
Most of my work with coding agents still starts the same way: I explain a task, wait for a result, review it, and send the next instruction.
The agent may write the code, but I am doing another job in the background. I keep track of what happened, decide what comes next, and determine when the work is actually finished.
In other words, I am the loop.
Peter Steinberger on moving from prompting agents to designing the loops around them. View the original post.
Loop engineering is the practice of designing the whole system around one or more agents. Instead of writing every prompt by hand, we decide how work is discovered, how context is provided, which actions are allowed, how results are checked, what the system remembers, and when a person needs to step in.
The loop is the feedback mechanism inside that system. It observes the current state, decides what to do, acts, checks what changed, and remembers enough to make the next cycle useful.
This makes loop engineering broader than running the same prompt on a timer or asking an agent to continue until it reaches a goal. Those are useful execution patterns, but they are only part of the design.
The bigger change is delegation. Until now, we could give an agent a task, but we still had to keep that task moving. We checked the result, supplied missing context, chose the next step, and decided when the work was done.
With a well-designed loop, we can delegate the ongoing work itself. We give the system an outcome and rely on it to manage the intermediate steps, use the right skills, check its progress, and return when it succeeds or needs help.
Within clear boundaries, we can fully delegate the ongoing work required to reach or maintain an outcome. The loop keeps observing, deciding, acting, verifying, and updating its state across many cycles. It escalates only when it cannot continue within those boundaries.
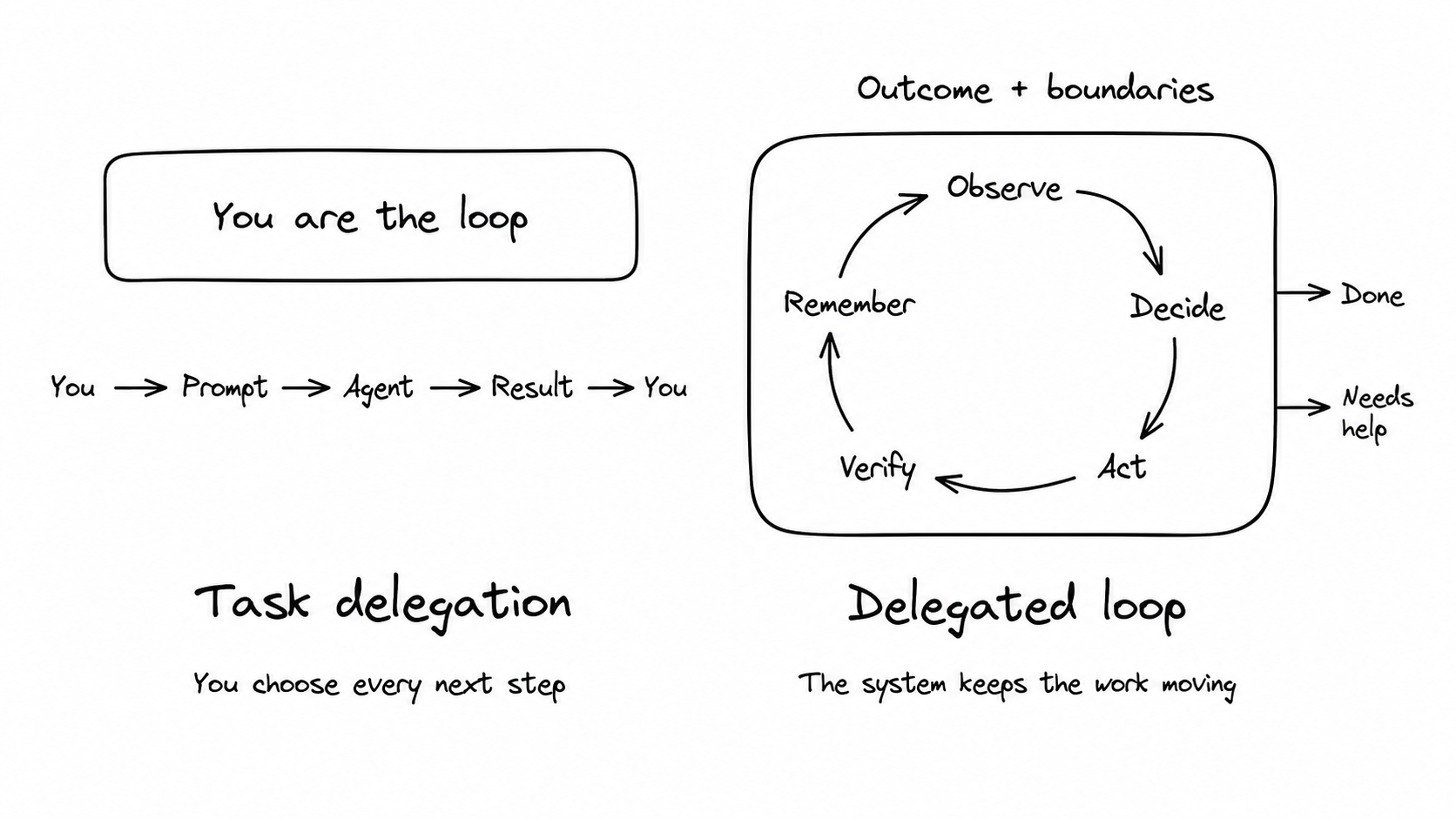
The shift is from delegating one step to delegating the ongoing work.
Goals and schedules are execution patterns
Once we have the system, we still need to decide what starts a cycle and what keeps it running. There are several common patterns.
A goal-driven loop keeps working until a condition becomes true. For example: keep investigating and fixing a pull request until its tests pass and there are no unresolved review comments.
A scheduled loop wakes up at a defined interval, checks what changed, and decides whether anything needs attention. For example: inspect active pull requests every ten minutes and act only when CI fails or new feedback arrives.
An event-driven loop starts when something happens. A failed CI job, a new review comment, or a changed ticket can trigger the next cycle immediately.
These patterns can work together. A scheduled loop might discover a failing pull request, then start a goal-driven loop to repair it. A new review comment might wake that loop again later.
The execution pattern is not the main point. The important part is the decision made on every cycle:
- What is the goal?
- What is true right now? (What is the current state?)
- What is the next useful action?
- How will we check the result?
- Should the loop continue, stop, or ask for help?
This framing is close to Michael Van Horn’s description: we write the intent and stopping behaviour, then the loop prompts the agent on each tick.
What this looks like in practice
Consider the pull-request example. A useful loop needs more than a prompt saying “fix the PR.” It needs a designed system around the task:
- Trigger: a schedule, a CI failure, or a new review comment.
- Goal: the pull request is green and ready for human review.
- State and memory: CI results, review comments, previous attempts, and open blockers.
- Skills and tools: repository knowledge, build commands, code editing, and pull-request access.
- Decision rules: what to inspect, when to edit, when to retry, and when to escalate.
- Verification: tests, linting, type checks, review status, and an independent review when needed.
- Limits: success, a fixed attempt count, a budget limit, or a blocker that requires a person.
Each cycle starts by reading the latest state. If CI is failing, the loop investigates the failure. If a reviewer has left a comment, it handles that instead. If everything is green, it stops.
The same structure can be used for dependency maintenance, issue triage, release preparation, test improvement, or documentation upkeep. The actions change, but the control loop is largely the same.
Repeated work should become a skill
Loops become useful when they stop rediscovering the same process.
If an agent must learn our build commands, repository conventions, and verification steps on every run, the loop will be slow and inconsistent. That knowledge should live in a reusable skill that the loop can call when needed.
I like Samuel McDonald’s rule of thumb: if you do something more than once, automate it as a skill; if you do something difficult, capture it afterward so it is cheaper next time.
This is how the system compounds. A difficult incident becomes a debugging skill. A repeated release process becomes a release skill. A long checklist becomes an executable routine instead of another document we hope somebody remembers to read.
Verification matters as much as action
An agent that writes code, checks its own work, and declares success is not a reliable loop.
Something in the system needs permission to say no. Sometimes that is deterministic: a test fails, the type checker reports an error, or a budget has been exhausted. Sometimes it is another agent reviewing the work against the original goal. For higher-risk changes, it is still a person.
Subagents are useful when they create a real separation of responsibilities. One can explore the problem, another can implement, and a third can verify the result. But adding agents also adds cost and coordination. A second agent is valuable when an independent opinion matters, not simply because more agents sound more autonomous.
The same principle applies to stopping. “The agent thinks it is done” is weak evidence. “The defined checks pass and an independent reviewer found no unmet requirement” is much stronger.
The “engineer” moves up one level
Here, the “engineer” does not have to be a software engineer. It is the person who owns the outcome and designs the system around it. That could be someone working in operations, research, sales, support, finance, or software.
Their job moves up one level. They spend less time sending the next obvious instruction and more time defining goals, boundaries, checks, memory, and escalation paths.
The system can own the ongoing work inside those boundaries. A person still owns the outcome. This separation is important because full delegation should reduce attention, not responsibility.
There is a risk here too. A loop can produce code faster than the team can understand it. That creates comprehension debt: the system keeps moving while our mental model falls behind. The answer is not maximum autonomy. It is the right amount of autonomy for the quality of our checks and our understanding of the work.
A company can be a set of loops
Let’s imagine this together. We are creating a new e-commerce company, but instead of thinking about it only as a website with a few agents attached to it, we think about it as a business made of loops.
Start with procurement. The loop wakes up every day, checks inventory, looks at sales velocity, compares supplier options, and decides whether anything needs to be restocked. If stock is low, it can reorder within a budget or find alternative suppliers. If the price changed too much or the supplier risk is unclear, it asks for help.
Marketing can be another loop. Its goal is not “run ads.” Its goal is to acquire customers below a target CAC within a defined budget. It has access to past campaigns, current performance, creative assets, and the tools needed to launch experiments. As long as the CAC is below the target and the budget has not run out, it keeps testing, measuring, and reallocating spend.
Support can run as a loop too. Every thirty minutes, it reads new customer questions, answers what it can from the knowledge base, and escalates what it cannot answer safely. The important part is that it also remembers what people keep asking. Repeated questions become documentation updates, product feedback, or signals that something in the funnel is unclear.
Then there is the bug loop. If customers report the same issue several times, the system can collect examples, reproduce the problem, open a ticket, and maybe even prepare a fix. For low-risk changes, it might ship after tests pass. For higher-risk changes, it can stop at a pull request and ask a person to review.
Product analytics can become another loop. Every day, it looks at cohorts, activation, drop-off, retention, and unusual behaviour. If it sees a pattern, it does not only explain what happened. It can change messaging, adjust the funnel, launch an A/B test, measure the result, and keep the version that works better. The loop is not just reporting numbers. It is acting, measuring again, and learning which changes improve the product.
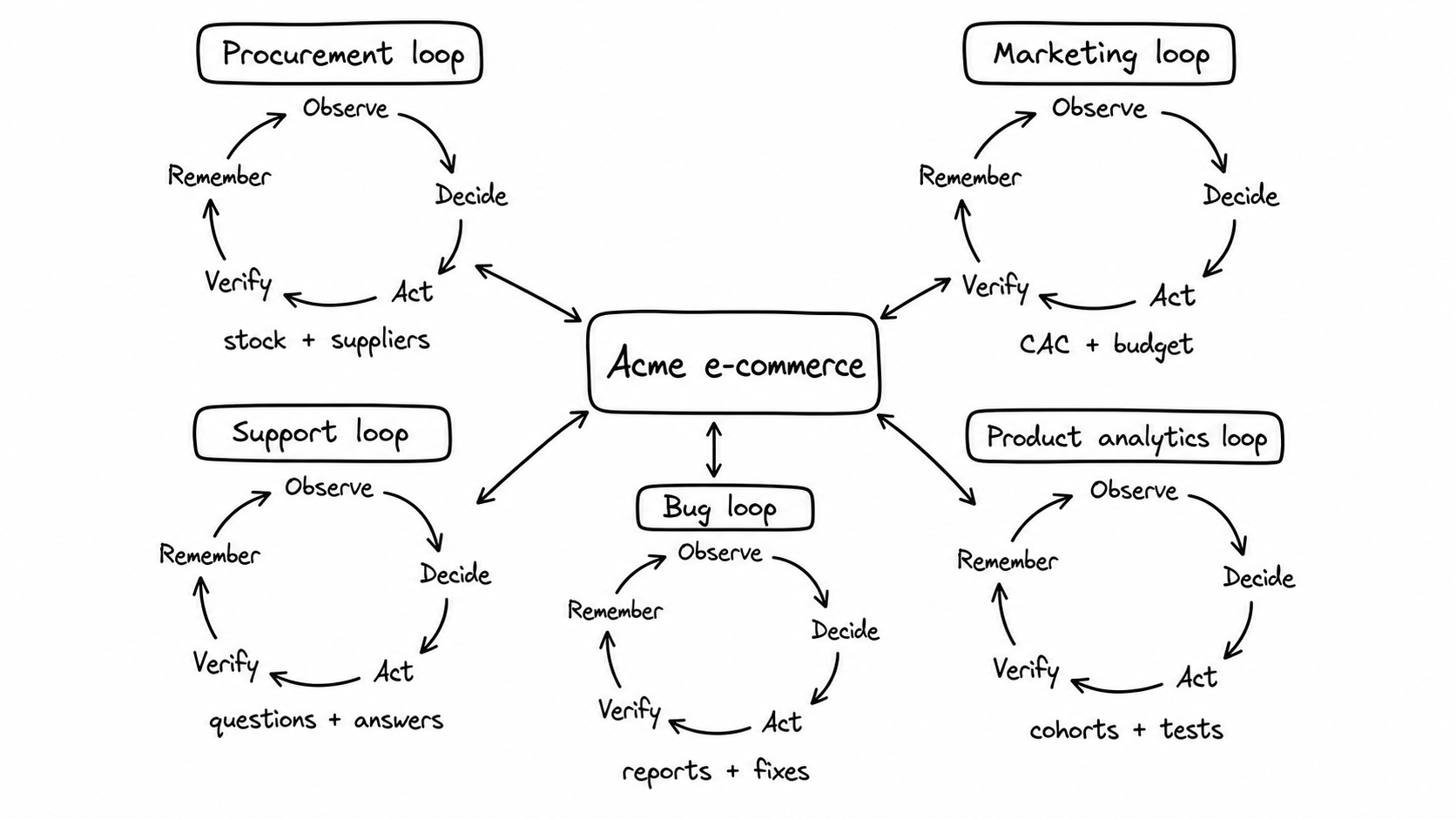
A business can contain many loops, each with its own goal, tools, memory, and escalation rules.
The autonomy level can be different for each loop. Procurement may be allowed to reorder cheap, low-risk inventory automatically. Marketing may be allowed to spend only within a daily budget. Support may answer common questions directly but escalate refunds or angry customers. Product analytics may be allowed to run small experiments by itself, while larger product changes still need a person to approve them.
The point is not to make every loop fully autonomous on day one. The point is to define the goal, boundaries, rules, memory, and checks clearly enough that the system can keep moving without asking for the next obvious instruction every time.
Pick one loop and start
The best starting point is a repeated task with a clear result, not a large autonomous development system.
Write down the goal and stopping condition. List the state the agent needs. Define the checks. Watch the first cycles closely. When a step repeats or requires hard-won knowledge, turn it into a skill. Increase autonomy only when the behaviour becomes predictable.
That is the practical promise of loop engineering: real delegation. We give the system an outcome, not just the next instruction. It can make reliable progress without needing us to press the button after every step.
The only thing you need to start doing this yourself is Codex. Open the Codex app, or download it if you do not have it yet, connect it to the data sources where your work already happens, and start creating automations and skills directly there. Pick one manual workflow, give Codex the right context and boundaries, and let it automate the work you already repeat.
LFG!