Improving GPTStore: Product Manager's Take
As you may know, I develop a popular customGPT called Ms. Smith for language learning. Recently, OpenAI asked for my thoughts on their GPTStore. As I am also a product manager, before talking to them, I thought about how I would approach improving GPTStore and identified the pain points that different user groups face when using GPTStore. Here’s what I noticed and how I’d start tackling these problems.
The Journey with GPTStore
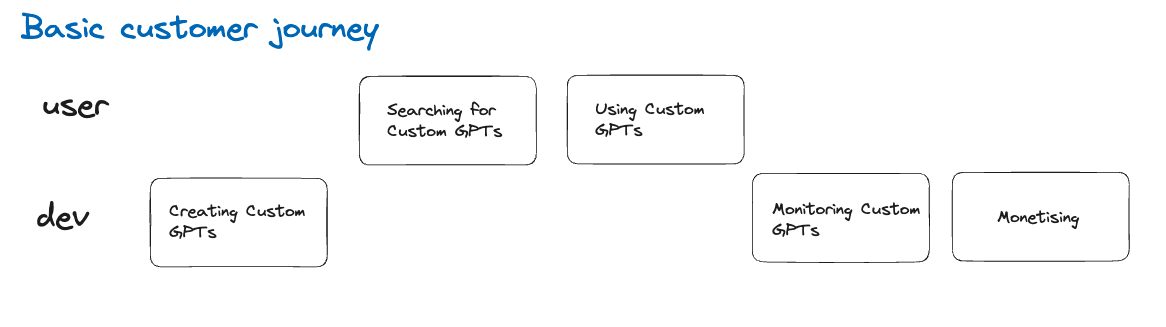 GPTStore is a place where users can find, use, and make their own CustomGPTs. They can also keep an eye on how these GPTs are doing and make money from them.
GPTStore is a place where users can find, use, and make their own CustomGPTs. They can also keep an eye on how these GPTs are doing and make money from them.
The Pain points through the User Journey
It is a good start; however, there are many pain points experienced by the two main user groups:
- User (end-user)
- Dev (GPT developer)
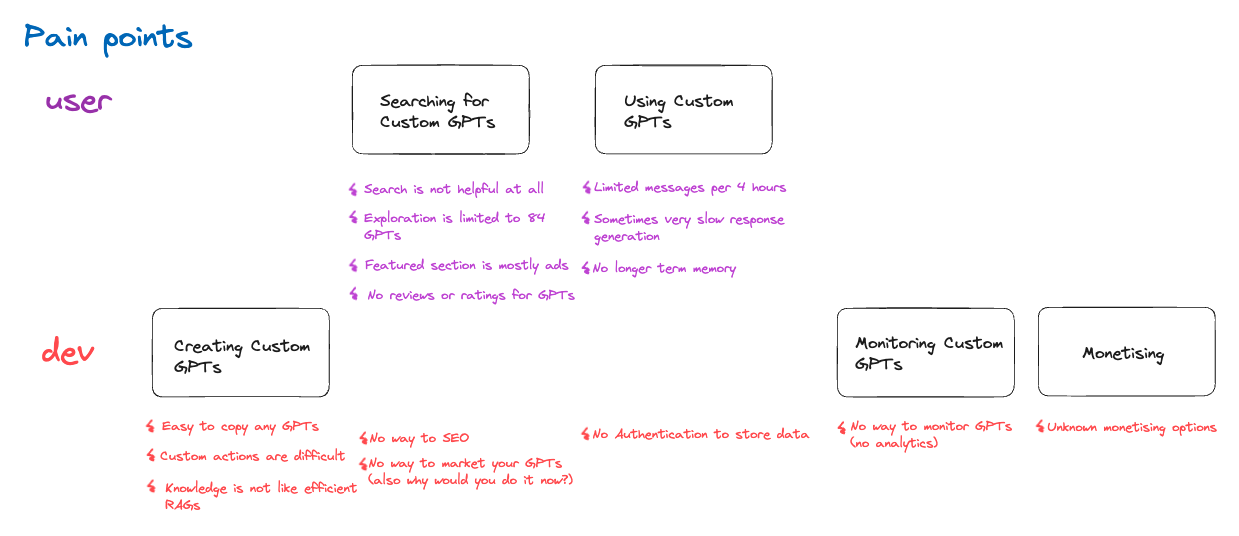
Let’s examine those pain points individually.
Creating Custom GPTs
⚡ Easy to copy any GPTs (dev + user)
The ease of creating custom GPTs is both a blessing and a curse. Upon the launch of GPTStore, an astonishing 3 million GPTs were already created. A closer inspection reveals numerous instances where identical GPTs are replicated up to 20 times. The absence of a quality control mechanism, akin to the approval process for iOS apps, leads to a proliferation of low-quality and duplicate GPTs.
⚡ Custom actions are difficult (dev)
Many developers in the community express frustration over the implementation of custom actions, citing difficulties in usability and bugs.
⚡ Knowledge is not like efficient RAGs (dev)
The approach to integrating Retrieval-Augmented Generation (RAG) using a one-size-fits-all strategy appears insufficient. It is clear that the initial setup of RAG, enhanced through prompt engineering, only scratches the surface of its potential, lacking advanced techniques like re-ranking and chunking.
Searching for GPTs
⚡ Search is not helpful at all (user)
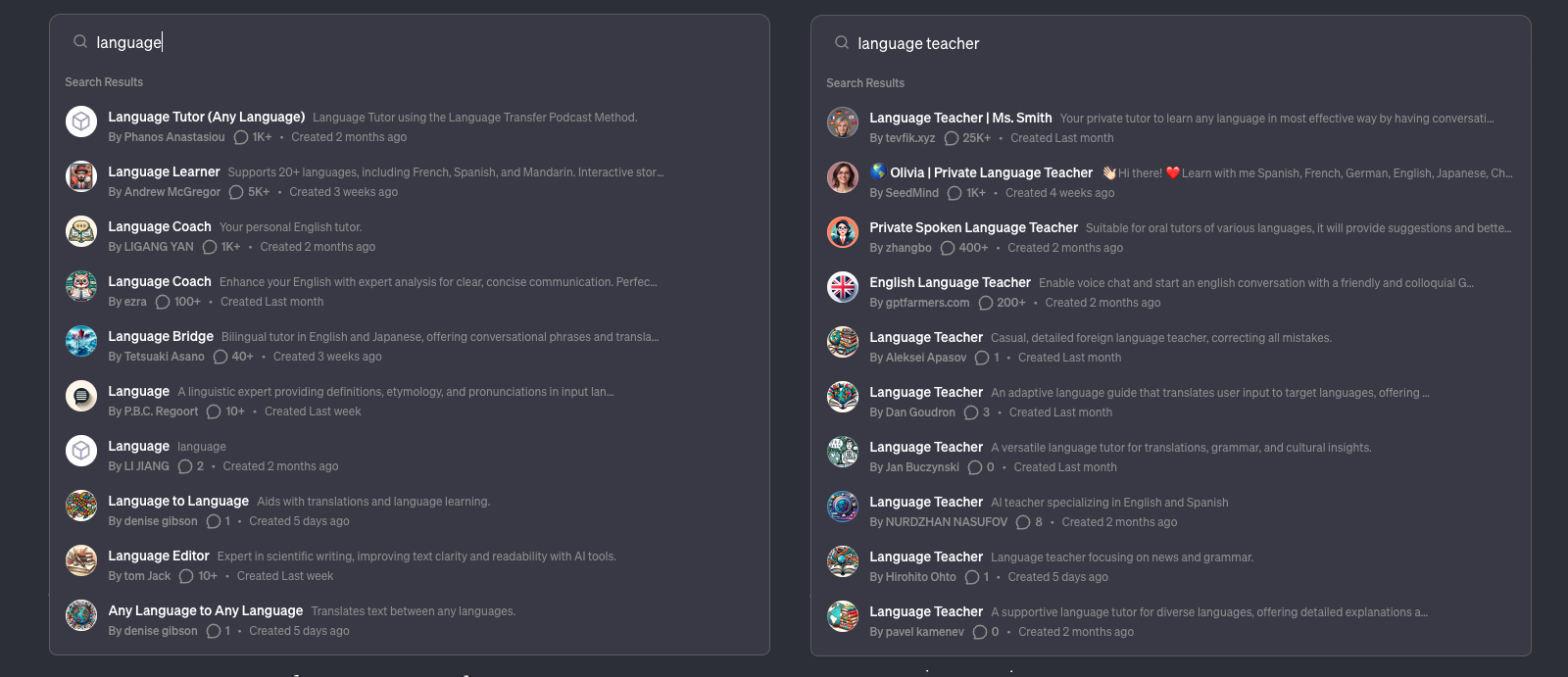
For instance, searching for “Language” in GPTStore fails to locate “Language Teacher | Ms. Smith,” illustrating the search function’s limitations.
⚡ Exploration is limited to 84 GPTs (user)
Currently, exploration through category rankings is confined to a mere 84 GPTs, presenting a significant barrier to discovery, particularly for new entries or smaller developers competing with prominent brands like Canva and Wolfram.
⚡ Featured section is mostly ads (user)
The criteria for selecting featured GPTs seem primarily driven by revenue objectives rather than fostering a diverse marketplace.
⚡ No reviews or ratings for GPTs (user)
The absence of review or rating systems for GPTs hampers users’ ability to share experiences, often leading to dissatisfaction with poorly developed GPTs.
⚡ No way to optimize for search engine optimization (SEO) (dev)
GPT creators cannot optimize for search engine queries. In the previous version, it was possible but with the update on the search, it has become impossible to be “discovered” by users.
⚡ No way to market your GPTs
The current landscape forces developers to seek alternative platforms (social media or other GPT external directories) for marketing their GPTs, as the in-house options are severely limited.
Using GPTs
⚡ Limited messages per 4 hours (user)
As a user, you have limited access to GPT-4 and, eventually, CustomGPTs. However, some GPTs do not require GPT-4 and are impacted by the limitations. Furthermore, some GPTs are designed for a single task with one instruction (e.g., create a video based on this topic), whereas some GPTs (like my Ms. Smith - Language Teacher) require a conversation to accomplish their goal.
⚡ Sometimes very slow response generation (user)
Similar to the challenge above, my personal feeling is that GPT-4 is sometimes too large a model for certain applications, and when the context becomes larger, it feels that responses get slower.
⚡ No longer term memory (user)
One of the other challenges is that ChatGPT and customGPTs do not have out-of-session memories. Imagine the use-case of my customGPT - language learning. Each time the user opens a session with it, it asks again what language they want to learn and what is their level? An app should have a state so that users would return more frequently to the app and focus on the core functionality from their first message.
⚡ No Authentication to store data (dev)
Even if the CustomGPTs have no memories, we (as devs) could store the data externally. It is also not possible, because there is no way to authenticate users securely at the moment.
Monitoring CustomGPTs
⚡ No way to monitor GPTs (dev)
I think this is one of my biggest personal pain points. I have no understanding of whether people enjoy using my Custom GPT. I would need metrics like:
- How many new vs returning users do I have?
- How long are the conversations (# messages in a conversation or even time for speaking/listening)?
- How many daily users do I have?
- How many are active?
- How is my GPT growing?
Monetising
⚡ Unknown monetising options
This pain point is crucial - because at the moment GPT developers like me do not know how much to invest into our customGPTs; we basically do not know the ROI.
Furthermore, for me personally, it was demotivating to read that US-creators will be paid before the European, and my first question was, “Why is this the case?”
Conclusion
I think it is crucial for OpenAI to address these pain points and solve some of them. The competition is fiercely increasing, and others are reaching out to OpenAI to gain an advantage.
Just 2 weeks ago, CTO of HuggingFace tweeted the following:
And then after 2 weeks, they have created their “Assistants”