Why LLM agents are dumb?
I’ve been thinking about agents a lot lately. You know what I’ve realized—something maybe obvious? They’re actually kind of… dumb!
I think they’re “dumb” because I have to design them in such detail: deciding how their planner should work, what tools they should use, how they should manage memory, and so on. But I don’t want to be doing all of that! I want them to suggest how they should function. I want to be the context-giver, the manager—not the engineer. This, I believe, is the thin line between smartness and dumbness in agents.
Sure, they can make decisions when given a planner and toolset, which is great and a big improvement over classical software engineering. However, I’m looking for the next step forward.
To me, this isn’t just a question of LLM capabilities. We’re missing key links between us, the agents, and the environment. LLMs feel like massive books with vast knowledge and incredible query speed, yet they lack a real understanding of the world and how to interact with it—or with us. They seem programmed to respond to anything due to their instruction-based training, but often they miss the mark on fully grasping the context or intent of a question.
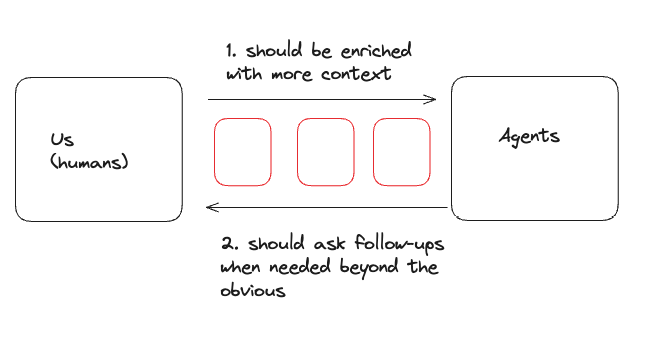
One solution for this could be creating “onboarding modules” for agents, so they can enrich their understanding of context through additional information from us, including aspects we might not initially think of or that seem obvious to us. I created a simple example of this in a basic custom GPT to show what an onboarding module might look like.
This is just a basic example, but I believe we need multiple levels of abstraction and enrichment steps between us and agents to help them gain a better understanding of our context and the world around them.
It’s not entirely related, but there was an online discussion this week about Moravec’s paradox, which argues that tasks simple for humans are not equally simple for robots or machines. This paradox reflects the gap we see with agents today.
Moravec's paradox in LLM evals
— Andrej Karpathy (@karpathy) November 10, 2024
I was reacting to this new benchmark of frontier math where LLMs only solve 2%. It was introduced because LLMs are increasingly crushing existing math benchmarks. The interesting issue is that even though by many accounts (/evals), LLMs are inching… https://t.co/3Ebm7MWX1G